diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat1.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat1.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat1.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat1.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat10.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat10.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat10.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat10.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat2.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat2.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat2.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat2.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat3.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat3.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat3.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat3.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat4.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat4.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat4.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat4.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat5.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat5.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat5.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat5.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat6.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat6.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat6.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat6.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat7.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat7.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat7.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat7.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat8.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat8.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat8.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat8.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat9.png b/docs/Services/Applications scientifiques/Labostat/img/image-labostat9.png
similarity index 100%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/img/image-labostat9.png
rename to docs/Services/Applications scientifiques/Labostat/img/image-labostat9.png
diff --git a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/procedure_labostat.md b/docs/Services/Applications scientifiques/Labostat/procedure_labostat.md
similarity index 96%
rename from docs/Services/pole-scientifique/Applications scientifiques/Procedure/procedure_labostat.md
rename to docs/Services/Applications scientifiques/Labostat/procedure_labostat.md
index c890fd0..fceab5c 100644
--- a/docs/Services/pole-scientifique/Applications scientifiques/Procedure/procedure_labostat.md
+++ b/docs/Services/Applications scientifiques/Labostat/procedure_labostat.md
@@ -1,59 +1,59 @@
-
-# Procédure première connexion au serveurs de calcul Labostat & Labostat2
-
-Vous venez d'obtenir l'accès aux serveurs de calcul Labostat & Labostat2, accessible depuis l'interface web: http://labostat.ensae.fr:8000/
-
-**Cependant** avant de pouvoir y accéder vous devez effectuer quelques manipulations afin de créer vos dossiers utilisateur sur ces serveurs.
-
-Pour ces manipulations il faut que vous soyez connecté sur le réseau interne du GENES ou connecté en Bureau à distance si vous êtes à l'extérieur (https://rdsgw.ensae.fr/RDWeb/Pages/fr-FR/Default.aspx).
-
-
-## Création d'un dossier utilisateur sur les serveurs
-
-Pour créer vos répertoires utilisateur il faut que vous vous connectez sur Labostat & Labostat2 en SSH. La procédure suivante est faite via CMD sur Windows, mais vous pouvez le faire via n'importe quel logiciel type ssh (putty etc...),
-
-Pour cela, lancer une console CMD:
- - Appuyer sur la touche Windows de votre clavier
- - Dans la barre de recherche écrivez "CMD" et appuyer sur entrer
-
-
-
-Une fenêtre d'invite de commande va s'ouvrir, vous aller devoir vous connecter au deux serveurs de calcul via ssh en utilisant vos identifiants ENSAE.
-
-Nous allons commencer par le labostat2 dont l'adresse ip est 172.16.200.17, pour cela écrivez la commande "%votre_nom_d'utilisateur_ensae%@172.16.200.17", appuyer sur la touche entrer, puis écrivez votre mot de passe ENSAE.
-Exemple:
- ssh aguyot@172.16.200.17
-
-
-
-
-Si la connexion s'est bien effectuée, vous devriez avoir comme l'image suivante et avoir en texte vert sur la console "votrelogin@labostat2":
-
-
-
-Vous devez refaire la manipulation suivante mais sur le serveur labostat dont l'adresse ip est 172.16.200.72 (attention, la connexion en ssh peu parfois s'annuler pour ce serveur, recommencer jusqu'à réussir à vous connecter au minimum une fois):
-Exemple:
- ssh aguyot@172.16.200.72
-
-
-
-
-## Connexion à l'interface jupyter
-
-Maintenant vos répertoires personnel créés, vous pouvez désormais utiliser l'interface web jupyter du serveur de calcul via le lien suivant: http://labostat.ensae.fr:8000/. Pour vous connecter, utiliser de nouveau vos identifiants ENSAE (les mêmes que vous avez utilisés précédemment), il peu y avoir de temps en temps une erreur de connexion, essayer plusieurs fois de vous reconnecter:
-
-
-
-Une fois connecter vous avez accès au cluster:
-
-
-Vous pouvez désormais faire vos travaux, exemple de création d'une matrice aléatoire de paramètre (n,p) avec le package torch:
-
-
-L'installation des packages se fait en local (c'est à dire sur le notebook) en utilisant la formule "pip install %nom_du_package%", voir la capture suivante pour une exponentielle avec le package scipy en utilisant "pip install scipy":
-
-
-Il est important de se déconnecter une fois que vous ne travaillez plus sur le cluster, cliquer sur l'onglet "File" en haut à gauche et cliquer sur "Log Out":
-
-
+
+# Procédure première connexion au serveurs de calcul Labostat & Labostat2
+
+Vous venez d'obtenir l'accès aux serveurs de calcul Labostat & Labostat2, accessible depuis l'interface web: http://labostat.ensae.fr:8000/
+
+**Cependant** avant de pouvoir y accéder vous devez effectuer quelques manipulations afin de créer vos dossiers utilisateur sur ces serveurs.
+
+Pour ces manipulations il faut que vous soyez connecté sur le réseau interne du GENES ou connecté en Bureau à distance si vous êtes à l'extérieur (https://rdsgw.ensae.fr/RDWeb/Pages/fr-FR/Default.aspx).
+
+
+## Création d'un dossier utilisateur sur les serveurs
+
+Pour créer vos répertoires utilisateur il faut que vous vous connectez sur Labostat & Labostat2 en SSH. La procédure suivante est faite via CMD sur Windows, mais vous pouvez le faire via n'importe quel logiciel type ssh (putty etc...),
+
+Pour cela, lancer une console CMD:
+ - Appuyer sur la touche Windows de votre clavier
+ - Dans la barre de recherche écrivez "CMD" et appuyer sur entrer
+
+
+
+Une fenêtre d'invite de commande va s'ouvrir, vous aller devoir vous connecter au deux serveurs de calcul via ssh en utilisant vos identifiants ENSAE.
+
+Nous allons commencer par le labostat2 dont l'adresse ip est 172.16.200.17, pour cela écrivez la commande "%votre_nom_d'utilisateur_ensae%@172.16.200.17", appuyer sur la touche entrer, puis écrivez votre mot de passe ENSAE.
+Exemple:
+ ssh aguyot@172.16.200.17
+
+
+
+
+Si la connexion s'est bien effectuée, vous devriez avoir comme l'image suivante et avoir en texte vert sur la console "votrelogin@labostat2":
+
+
+
+Vous devez refaire la manipulation suivante mais sur le serveur labostat dont l'adresse ip est 172.16.200.72 (attention, la connexion en ssh peu parfois s'annuler pour ce serveur, recommencer jusqu'à réussir à vous connecter au minimum une fois):
+Exemple:
+ ssh aguyot@172.16.200.72
+
+
+
+
+## Connexion à l'interface jupyter
+
+Maintenant vos répertoires personnel créés, vous pouvez désormais utiliser l'interface web jupyter du serveur de calcul via le lien suivant: http://labostat.ensae.fr:8000/. Pour vous connecter, utiliser de nouveau vos identifiants ENSAE (les mêmes que vous avez utilisés précédemment), il peu y avoir de temps en temps une erreur de connexion, essayer plusieurs fois de vous reconnecter:
+
+
+
+Une fois connecter vous avez accès au cluster:
+
+
+Vous pouvez désormais faire vos travaux, exemple de création d'une matrice aléatoire de paramètre (n,p) avec le package torch:
+
+
+L'installation des packages se fait en local (c'est à dire sur le notebook) en utilisant la formule "pip install %nom_du_package%", voir la capture suivante pour une exponentielle avec le package scipy en utilisant "pip install scipy":
+
+
+Il est important de se déconnecter une fois que vous ne travaillez plus sur le cluster, cliquer sur l'onglet "File" en haut à gauche et cliquer sur "Log Out":
+
+
Pour réaccéder au cluster, il suffit simplement de vous connecter via l'adresse: http://labostat.ensae.fr:8000/
\ No newline at end of file
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/Condition d'utilisation Onyxia GENES b/docs/Services/Onyxia/img/Condition d'utilisation Onyxia GENES
similarity index 97%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/Condition d'utilisation Onyxia GENES
rename to docs/Services/Onyxia/img/Condition d'utilisation Onyxia GENES
index 9a20ede..1918743 100644
--- a/docs/Services/pole-scientifique/Onyxia/docs/img/Condition d'utilisation Onyxia GENES
+++ b/docs/Services/Onyxia/img/Condition d'utilisation Onyxia GENES
@@ -1,225 +1,225 @@
-CECI EST UNE COPIE DES CONDITIONS D’UTILISATION D'ONYXIA SSPCLOUD NON MODIFIER (https://www.sspcloud.fr/tos_fr.md)
-
-# Conditions générales d'utilisation (dernière mise à jour : 21 juin 2021)
-
-## Présentation / Fonctionnalités
-
-Le datalab "SSP Cloud" est un service (ci après désigné par "le
-Service") mis en œuvre par l'Institut national de la statistique et des
-études économiques (ci-après dénommé "l'Insee").
-
-Le SSP Cloud est une implémentation du logiciel libre
-[Onyxia](https://www.onyxia.sh/) créé et maintenu par la
-division innovation et instruction technique de l'Insee (direction du
-système d'information/unité innovation et stratégie du système
-d'information). L'hébergement du SSP Cloud est assuré par l'Insee.
-
-Le SSP Cloud est une plateforme proposant un "datalab" destiné aux
-expérimentations de _data science_ sur données ouvertes dans lequel les
-utilisateurs peuvent orchestrer des services dédiés à la pratique de la
-_data science_ (environnements de développement, bases de données...).
-Cette offre de services vise ainsi à familiariser les utilisateurs avec
-de nouvelles méthodes de travail collaboratif mobilisant des langages
-statistiques _open source_ (R, python, Julia...), des technologies de
-type _cloud computing_ ainsi qu'à permettre d'expérimenter des
-traitements statistiques innovants. Les services proposés sont
-standards.
-
-Le SSP Cloud s'adresse à des agents publics ainsi qu'aux enseignants et
-étudiants du Groupe des écoles nationales d'économie et de statistique,
-permettant une collaboration interservices et la coopération avec leur
-écosystème. Des accès peuvent également être accordés sur demande et
-après décision des organes de gouvernance du SSP Cloud à des
-collaborateurs extérieurs et impliqués dans la réalisation de projets
-expérimentaux du système statistique public.
-
-Le SSP Cloud permet :
-
-- l'orchestration de formations de _data science_
-- l'accès à des services de _data science_
-- le stockage sécurisé de données
-- la gestion de secrets, tels que des clés de chiffrement
-- l'accès à un service de gestion de code
-- l'orchestration de flux de traitement de données
-
-Un compte utilisateur permet également de se connecter à la plateforme
-de services de la communauté Mutualisation Inter-ministérielle Logiciels
-Libres ().
-
-## Modalités d'utilisation du Service
-
-Le datalab SSP Cloud est accessible depuis n'importe quel navigateur
-connecté à Internet. L'utilisation d'un ordinateur est recommandée.
-L'utilisation des services du datalab est gratuite.
-
-La communauté d'utilisateurs est accessible sur :
-
-- Tchap, salon [SSP
- Cloud](https://www.tchap.gouv.fr/#/room/#SSPCloudXDpAw6v:agent.finances.tchap.gouv.fr)
-- Rocket Chat du MIM Libre, salon [SSP
- Cloud](https://chat.mim-libre.fr/channel/sspcloud)
-
-## Limites d'utilisation du Service
-
-Peuvent être traitées sur le datalab les données publiques et données
-usuelles (données de travail sans sensibilité particulière).
-
-Le dépôt de toute donnée directement identifiante (noms, prénoms, etc.),
-même déjà disponible publiquement, est proscrit.
-
-En l'absence d'autorisation spécifique pour un projet d'expérimentation
-donné, ne peuvent être traitées sur le datalab les données "protégées"
-ou "sensibles", avec ou sans marque de confidentialité destinée à
-restreindre la diffusion à un domaine spécifique (secret statistique,
-commercial, industriel...).
-
-Le caractère "protégé" ou "sensible" des informations stockées ou
-traitées sur le datalab est soumis à l'appréciation de l'utilisateur
-sous la responsabilité de sa hiérarchie.
-
-La réalisation de traitements à des fins de contrôle fiscal ou de
-répression économique est proscrite.
-
-## Les rôles, engagements et responsabilités associées
-
-Le Service est mis à disposition par l'Insee sans autres garanties
-expresses ou tacites que celles qui sont prévues par les présentes. Le
-Service s'appuie sur des technologies open source de référence.
-Toutefois, il n'est pas garanti qu'il soit exempt d'anomalies ou
-erreurs. Le Service est donc mis à disposition **sans garantie sur sa
-disponibilité et ses performances**. A ce titre, l'Insee ne peut être
-tenu responsable des pertes et/ou préjudices, de quelque nature qu'ils
-soient, qui pourraient être causés à la suite d'un dysfonctionnement ou
-une indisponibilité du Service. De telles situations n'ouvriront droit à
-aucune compensation financière.
-
-Chaque utilisateur dispose d'un espace de stockage personnel. Par
-défaut, toutes les informations déposées dans un espace de stockage d'un
-utilisateur ne sont accessibles qu'à lui seul. Chaque utilisateur a la
-possibilité de rendre publics des fichiers stockés dans son espace de
-stockage personnel. Chaque utilisateur est responsable de la mise à
-disposition publique de ses fichiers.
-
-Chaque utilisateur agit sous la responsabilité de sa hiérarchie. Il doit
-s'assurer auprès de sa hiérarchie qu'en cas de traitement de données à
-caractère personnel réalisés à l'aide du SSP Cloud, ceux-ci ont bien été
-déclarés au délégué à la protection des données de sa structure.
-
-Chaque utilisateur s'engage, lors de l'utilisation qu'il fera de la
-plateforme, à ne pas contrevenir aux dispositions législatives et
-réglementaires en vigueur et aux présentes conditions générales
-d'utilisation. Il est informé que toute violation desdites dispositions
-est susceptible d'entraîner des poursuites judiciaires et sanctions à
-son encontre.
-
-Les ressources du Service étant mutualisées entre utilisateurs, toute
-utilisation excessive pourra faire l'objet d'une suspension partielle ou
-totale, sans préavis, de l'accès au Service. Ces mesures, visant au bon
-fonctionnement du Service, sont laissées à la libre appréciation des
-administrateurs du Service.
-
-## La création de compte sur le SSP Cloud
-
-L'accès au SSP Cloud nécessite une inscription préalable et une
-authentification.
-L'inscription et l'authentification peuvent être réalisées grâce au
-service AgentConnect.
-
-## Les projets d'expérimentation sur données non ouvertes
-
-Sur décision des organes de gouvernance du SSP Cloud, des projets
-d'expérimentation mobilisant des données non ouvertes peuvent être menés
-sur le SSP Cloud. La décision précise les utilisateurs habilités à
-participer à ces projets.
-
-Les participants à un projet d'expérimentation sur données non ouvertes
-doivent impérativement se conformer aux règles de sécurité spécifiques à
-ce projet. Ils devront notamment utiliser exclusivement les espaces
-collaboratifs dédiés à ce projet et à toute procédure d'habilitation
-préalable qui serait nécessaire en particulier par le comité du secret
-statistique.
-
-## Propriété intellectuelle
-
-### Droits de propriété intellectuelle afférents à la plateforme
-
-L'Insee est titulaire de l'ensemble des droits de propriété
-intellectuelle afférents à la plateforme.
-
-Les utilisateurs s'engagent à ne pas utiliser le Service d'une manière
-qui serait constitutive d'une violation ou d'une atteinte aux lois et
-règlements de droit français.
-
-### Droits de propriété intellectuelle afférents aux marques et logos
-
-L'Insee est titulaire des droits de propriété intellectuelle des visuels
-qui figurent sur la plateforme.
-
-Ces derniers ne peuvent pas être utilisés sans l'autorisation écrite et
-préalable de l'Insee.
-
-Tout usage ou apposition totale ou partielle de ces visuels sans
-l'autorisation expresse et préalable de l'Insee est sanctionnée par
-l'article L. 716-1 du code de la propriété intellectuelle.
-
-### Droits de propriété intellectuelle afférents aux contenus de la plateforme
-
-Certains documents présents sur la plateforme sont susceptibles d'être
-soumis à des droits de propriété intellectuelle. Leur réutilisation est
-dans ce cas soumise à l'autorisation préalable des titulaires de ces
-droits.
-
-## Obligations relatives aux données que les utilisateurs peuvent déposer sur la plateforme
-
-Le traitement de données à caractère personnel au sens des articles 9 et
-10 du règlement général sur la protection des données (origine raciale
-ou ethnique, opinions politiques, convictions religieuses ou
-philosophiques, appartenance syndicale, condamnations pénales, état de
-santé passé, présent ou futur, orientation sexuelle, vie sexuelle...)
-est proscrit sur ce Service.
-
-Les données à caractère personnel traitées dans le cadre d'une
-expérimentation réalisée par un utilisateur, quand il y en a, relèvent
-de la responsabilité de l'entité administrative dont est issu
-l'utilisateur. Les dispositions relatives à leur traitement doivent être
-communiquées par l'utilisateur au délégué à la protection des données de
-son entité administrative de rattachement.
-
-Chaque utilisateur s'engage à souscrire aux obligations résultant d'une
-part de la loi n° 78-17 du 6 janvier 1978 modifiée relative à
-l'informatique, aux fichiers et aux libertés et d'autre part du
-règlement (UE) 2016/679 du 27 avril 2016 (règlement général sur la
-protection des données).
-
-L'utilisateur s'engage en outre à ne déposer sur la plateforme aucune
-donnée directement identifiante.
-Ainsi, seul le dépôt de données après au-moins pseudonymisation est
-autorisé. Tout utilisateur qui mettrait en œuvre un traitement
-non-conforme verra son accès au Service immédiatement supprimé.
-
-## Modification et évolution du Service
-
-L'Insee se réserve la liberté de faire évoluer, de modifier ou de
-suspendre, sans préavis, le Service pour des raisons de maintenance ou
-pour tout autre motif jugé nécessaire. L'information est alors
-communiquée aux utilisateurs via Tchap. Les termes des présentes
-conditions d'utilisation peuvent être modifiés ou complétés à tout
-moment, sans préavis, en fonction des modifications apportées au
-Service, de l'évolution de la législation ou pour tout autre motif jugé
-nécessaire. Ces modifications et mises à jour s'imposent à l'utilisateur
-qui doit, en conséquence, se référer régulièrement à cette rubrique pour
-vérifier les conditions générales en vigueur (accessible depuis la page
-d'accueil).
-
-## Loi applicable - Litiges
-
-Le Service et les présentes conditions générales d'utilisation sont
-soumis à la législation française. En cas de litige, les tribunaux
-français seront compétents.
-
-## Contact
-
-Pour les problèmes techniques et/ou fonctionnels rencontrés sur la
-plateforme, il est conseillé, dans un premier temps de solliciter les
-communautés de pairs dans les espaces collaboratifs prévus à cet effet
-sur Tchap et Rocket Chat-MIM Libre.
+CECI EST UNE COPIE DES CONDITIONS D’UTILISATION D'ONYXIA SSPCLOUD NON MODIFIER (https://www.sspcloud.fr/tos_fr.md)
+
+# Conditions générales d'utilisation (dernière mise à jour : 21 juin 2021)
+
+## Présentation / Fonctionnalités
+
+Le datalab "SSP Cloud" est un service (ci après désigné par "le
+Service") mis en œuvre par l'Institut national de la statistique et des
+études économiques (ci-après dénommé "l'Insee").
+
+Le SSP Cloud est une implémentation du logiciel libre
+[Onyxia](https://www.onyxia.sh/) créé et maintenu par la
+division innovation et instruction technique de l'Insee (direction du
+système d'information/unité innovation et stratégie du système
+d'information). L'hébergement du SSP Cloud est assuré par l'Insee.
+
+Le SSP Cloud est une plateforme proposant un "datalab" destiné aux
+expérimentations de _data science_ sur données ouvertes dans lequel les
+utilisateurs peuvent orchestrer des services dédiés à la pratique de la
+_data science_ (environnements de développement, bases de données...).
+Cette offre de services vise ainsi à familiariser les utilisateurs avec
+de nouvelles méthodes de travail collaboratif mobilisant des langages
+statistiques _open source_ (R, python, Julia...), des technologies de
+type _cloud computing_ ainsi qu'à permettre d'expérimenter des
+traitements statistiques innovants. Les services proposés sont
+standards.
+
+Le SSP Cloud s'adresse à des agents publics ainsi qu'aux enseignants et
+étudiants du Groupe des écoles nationales d'économie et de statistique,
+permettant une collaboration interservices et la coopération avec leur
+écosystème. Des accès peuvent également être accordés sur demande et
+après décision des organes de gouvernance du SSP Cloud à des
+collaborateurs extérieurs et impliqués dans la réalisation de projets
+expérimentaux du système statistique public.
+
+Le SSP Cloud permet :
+
+- l'orchestration de formations de _data science_
+- l'accès à des services de _data science_
+- le stockage sécurisé de données
+- la gestion de secrets, tels que des clés de chiffrement
+- l'accès à un service de gestion de code
+- l'orchestration de flux de traitement de données
+
+Un compte utilisateur permet également de se connecter à la plateforme
+de services de la communauté Mutualisation Inter-ministérielle Logiciels
+Libres ().
+
+## Modalités d'utilisation du Service
+
+Le datalab SSP Cloud est accessible depuis n'importe quel navigateur
+connecté à Internet. L'utilisation d'un ordinateur est recommandée.
+L'utilisation des services du datalab est gratuite.
+
+La communauté d'utilisateurs est accessible sur :
+
+- Tchap, salon [SSP
+ Cloud](https://www.tchap.gouv.fr/#/room/#SSPCloudXDpAw6v:agent.finances.tchap.gouv.fr)
+- Rocket Chat du MIM Libre, salon [SSP
+ Cloud](https://chat.mim-libre.fr/channel/sspcloud)
+
+## Limites d'utilisation du Service
+
+Peuvent être traitées sur le datalab les données publiques et données
+usuelles (données de travail sans sensibilité particulière).
+
+Le dépôt de toute donnée directement identifiante (noms, prénoms, etc.),
+même déjà disponible publiquement, est proscrit.
+
+En l'absence d'autorisation spécifique pour un projet d'expérimentation
+donné, ne peuvent être traitées sur le datalab les données "protégées"
+ou "sensibles", avec ou sans marque de confidentialité destinée à
+restreindre la diffusion à un domaine spécifique (secret statistique,
+commercial, industriel...).
+
+Le caractère "protégé" ou "sensible" des informations stockées ou
+traitées sur le datalab est soumis à l'appréciation de l'utilisateur
+sous la responsabilité de sa hiérarchie.
+
+La réalisation de traitements à des fins de contrôle fiscal ou de
+répression économique est proscrite.
+
+## Les rôles, engagements et responsabilités associées
+
+Le Service est mis à disposition par l'Insee sans autres garanties
+expresses ou tacites que celles qui sont prévues par les présentes. Le
+Service s'appuie sur des technologies open source de référence.
+Toutefois, il n'est pas garanti qu'il soit exempt d'anomalies ou
+erreurs. Le Service est donc mis à disposition **sans garantie sur sa
+disponibilité et ses performances**. A ce titre, l'Insee ne peut être
+tenu responsable des pertes et/ou préjudices, de quelque nature qu'ils
+soient, qui pourraient être causés à la suite d'un dysfonctionnement ou
+une indisponibilité du Service. De telles situations n'ouvriront droit à
+aucune compensation financière.
+
+Chaque utilisateur dispose d'un espace de stockage personnel. Par
+défaut, toutes les informations déposées dans un espace de stockage d'un
+utilisateur ne sont accessibles qu'à lui seul. Chaque utilisateur a la
+possibilité de rendre publics des fichiers stockés dans son espace de
+stockage personnel. Chaque utilisateur est responsable de la mise à
+disposition publique de ses fichiers.
+
+Chaque utilisateur agit sous la responsabilité de sa hiérarchie. Il doit
+s'assurer auprès de sa hiérarchie qu'en cas de traitement de données à
+caractère personnel réalisés à l'aide du SSP Cloud, ceux-ci ont bien été
+déclarés au délégué à la protection des données de sa structure.
+
+Chaque utilisateur s'engage, lors de l'utilisation qu'il fera de la
+plateforme, à ne pas contrevenir aux dispositions législatives et
+réglementaires en vigueur et aux présentes conditions générales
+d'utilisation. Il est informé que toute violation desdites dispositions
+est susceptible d'entraîner des poursuites judiciaires et sanctions à
+son encontre.
+
+Les ressources du Service étant mutualisées entre utilisateurs, toute
+utilisation excessive pourra faire l'objet d'une suspension partielle ou
+totale, sans préavis, de l'accès au Service. Ces mesures, visant au bon
+fonctionnement du Service, sont laissées à la libre appréciation des
+administrateurs du Service.
+
+## La création de compte sur le SSP Cloud
+
+L'accès au SSP Cloud nécessite une inscription préalable et une
+authentification.
+L'inscription et l'authentification peuvent être réalisées grâce au
+service AgentConnect.
+
+## Les projets d'expérimentation sur données non ouvertes
+
+Sur décision des organes de gouvernance du SSP Cloud, des projets
+d'expérimentation mobilisant des données non ouvertes peuvent être menés
+sur le SSP Cloud. La décision précise les utilisateurs habilités à
+participer à ces projets.
+
+Les participants à un projet d'expérimentation sur données non ouvertes
+doivent impérativement se conformer aux règles de sécurité spécifiques à
+ce projet. Ils devront notamment utiliser exclusivement les espaces
+collaboratifs dédiés à ce projet et à toute procédure d'habilitation
+préalable qui serait nécessaire en particulier par le comité du secret
+statistique.
+
+## Propriété intellectuelle
+
+### Droits de propriété intellectuelle afférents à la plateforme
+
+L'Insee est titulaire de l'ensemble des droits de propriété
+intellectuelle afférents à la plateforme.
+
+Les utilisateurs s'engagent à ne pas utiliser le Service d'une manière
+qui serait constitutive d'une violation ou d'une atteinte aux lois et
+règlements de droit français.
+
+### Droits de propriété intellectuelle afférents aux marques et logos
+
+L'Insee est titulaire des droits de propriété intellectuelle des visuels
+qui figurent sur la plateforme.
+
+Ces derniers ne peuvent pas être utilisés sans l'autorisation écrite et
+préalable de l'Insee.
+
+Tout usage ou apposition totale ou partielle de ces visuels sans
+l'autorisation expresse et préalable de l'Insee est sanctionnée par
+l'article L. 716-1 du code de la propriété intellectuelle.
+
+### Droits de propriété intellectuelle afférents aux contenus de la plateforme
+
+Certains documents présents sur la plateforme sont susceptibles d'être
+soumis à des droits de propriété intellectuelle. Leur réutilisation est
+dans ce cas soumise à l'autorisation préalable des titulaires de ces
+droits.
+
+## Obligations relatives aux données que les utilisateurs peuvent déposer sur la plateforme
+
+Le traitement de données à caractère personnel au sens des articles 9 et
+10 du règlement général sur la protection des données (origine raciale
+ou ethnique, opinions politiques, convictions religieuses ou
+philosophiques, appartenance syndicale, condamnations pénales, état de
+santé passé, présent ou futur, orientation sexuelle, vie sexuelle...)
+est proscrit sur ce Service.
+
+Les données à caractère personnel traitées dans le cadre d'une
+expérimentation réalisée par un utilisateur, quand il y en a, relèvent
+de la responsabilité de l'entité administrative dont est issu
+l'utilisateur. Les dispositions relatives à leur traitement doivent être
+communiquées par l'utilisateur au délégué à la protection des données de
+son entité administrative de rattachement.
+
+Chaque utilisateur s'engage à souscrire aux obligations résultant d'une
+part de la loi n° 78-17 du 6 janvier 1978 modifiée relative à
+l'informatique, aux fichiers et aux libertés et d'autre part du
+règlement (UE) 2016/679 du 27 avril 2016 (règlement général sur la
+protection des données).
+
+L'utilisateur s'engage en outre à ne déposer sur la plateforme aucune
+donnée directement identifiante.
+Ainsi, seul le dépôt de données après au-moins pseudonymisation est
+autorisé. Tout utilisateur qui mettrait en œuvre un traitement
+non-conforme verra son accès au Service immédiatement supprimé.
+
+## Modification et évolution du Service
+
+L'Insee se réserve la liberté de faire évoluer, de modifier ou de
+suspendre, sans préavis, le Service pour des raisons de maintenance ou
+pour tout autre motif jugé nécessaire. L'information est alors
+communiquée aux utilisateurs via Tchap. Les termes des présentes
+conditions d'utilisation peuvent être modifiés ou complétés à tout
+moment, sans préavis, en fonction des modifications apportées au
+Service, de l'évolution de la législation ou pour tout autre motif jugé
+nécessaire. Ces modifications et mises à jour s'imposent à l'utilisateur
+qui doit, en conséquence, se référer régulièrement à cette rubrique pour
+vérifier les conditions générales en vigueur (accessible depuis la page
+d'accueil).
+
+## Loi applicable - Litiges
+
+Le Service et les présentes conditions générales d'utilisation sont
+soumis à la législation française. En cas de litige, les tribunaux
+français seront compétents.
+
+## Contact
+
+Pour les problèmes techniques et/ou fonctionnels rencontrés sur la
+plateforme, il est conseillé, dans un premier temps de solliciter les
+communautés de pairs dans les espaces collaboratifs prévus à cet effet
+sur Tchap et Rocket Chat-MIM Libre.
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/favicon.ico b/docs/Services/Onyxia/img/favicon.ico
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/favicon.ico
rename to docs/Services/Onyxia/img/favicon.ico
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes.png b/docs/Services/Onyxia/img/git-genes.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/git-genes.png
rename to docs/Services/Onyxia/img/git-genes.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes2.png b/docs/Services/Onyxia/img/git-genes2.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/git-genes2.png
rename to docs/Services/Onyxia/img/git-genes2.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes3.png b/docs/Services/Onyxia/img/git-genes3.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/git-genes3.png
rename to docs/Services/Onyxia/img/git-genes3.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-10.png b/docs/Services/Onyxia/img/gitgenes-10.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-10.png
rename to docs/Services/Onyxia/img/gitgenes-10.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-5.png b/docs/Services/Onyxia/img/gitgenes-5.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-5.png
rename to docs/Services/Onyxia/img/gitgenes-5.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-6.png b/docs/Services/Onyxia/img/gitgenes-6.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-6.png
rename to docs/Services/Onyxia/img/gitgenes-6.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-7.png b/docs/Services/Onyxia/img/gitgenes-7.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-7.png
rename to docs/Services/Onyxia/img/gitgenes-7.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-8.png b/docs/Services/Onyxia/img/gitgenes-8.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-8.png
rename to docs/Services/Onyxia/img/gitgenes-8.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-9.png b/docs/Services/Onyxia/img/gitgenes-9.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/gitgenes-9.png
rename to docs/Services/Onyxia/img/gitgenes-9.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/github-token.png b/docs/Services/Onyxia/img/github-token.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/github-token.png
rename to docs/Services/Onyxia/img/github-token.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image1.png b/docs/Services/Onyxia/img/image1.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image1.png
rename to docs/Services/Onyxia/img/image1.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image10.png b/docs/Services/Onyxia/img/image10.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image10.png
rename to docs/Services/Onyxia/img/image10.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image11.png b/docs/Services/Onyxia/img/image11.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image11.png
rename to docs/Services/Onyxia/img/image11.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image12.png b/docs/Services/Onyxia/img/image12.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image12.png
rename to docs/Services/Onyxia/img/image12.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image13.png b/docs/Services/Onyxia/img/image13.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image13.png
rename to docs/Services/Onyxia/img/image13.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image14.png b/docs/Services/Onyxia/img/image14.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image14.png
rename to docs/Services/Onyxia/img/image14.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image15.png b/docs/Services/Onyxia/img/image15.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image15.png
rename to docs/Services/Onyxia/img/image15.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image16.png b/docs/Services/Onyxia/img/image16.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image16.png
rename to docs/Services/Onyxia/img/image16.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image17.png b/docs/Services/Onyxia/img/image17.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image17.png
rename to docs/Services/Onyxia/img/image17.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image18.png b/docs/Services/Onyxia/img/image18.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image18.png
rename to docs/Services/Onyxia/img/image18.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image19.png b/docs/Services/Onyxia/img/image19.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image19.png
rename to docs/Services/Onyxia/img/image19.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image2.png b/docs/Services/Onyxia/img/image2.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image2.png
rename to docs/Services/Onyxia/img/image2.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image20.png b/docs/Services/Onyxia/img/image20.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image20.png
rename to docs/Services/Onyxia/img/image20.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image21.png b/docs/Services/Onyxia/img/image21.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image21.png
rename to docs/Services/Onyxia/img/image21.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image22.png b/docs/Services/Onyxia/img/image22.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image22.png
rename to docs/Services/Onyxia/img/image22.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image23.png b/docs/Services/Onyxia/img/image23.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image23.png
rename to docs/Services/Onyxia/img/image23.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image24.png b/docs/Services/Onyxia/img/image24.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image24.png
rename to docs/Services/Onyxia/img/image24.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image25.png b/docs/Services/Onyxia/img/image25.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image25.png
rename to docs/Services/Onyxia/img/image25.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image26.png b/docs/Services/Onyxia/img/image26.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image26.png
rename to docs/Services/Onyxia/img/image26.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image27.png b/docs/Services/Onyxia/img/image27.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image27.png
rename to docs/Services/Onyxia/img/image27.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image28.png b/docs/Services/Onyxia/img/image28.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image28.png
rename to docs/Services/Onyxia/img/image28.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image29.png b/docs/Services/Onyxia/img/image29.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image29.png
rename to docs/Services/Onyxia/img/image29.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image3.png b/docs/Services/Onyxia/img/image3.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image3.png
rename to docs/Services/Onyxia/img/image3.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image31.png b/docs/Services/Onyxia/img/image31.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image31.png
rename to docs/Services/Onyxia/img/image31.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image32.png b/docs/Services/Onyxia/img/image32.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image32.png
rename to docs/Services/Onyxia/img/image32.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image33.png b/docs/Services/Onyxia/img/image33.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image33.png
rename to docs/Services/Onyxia/img/image33.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image4.png b/docs/Services/Onyxia/img/image4.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image4.png
rename to docs/Services/Onyxia/img/image4.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image5.png b/docs/Services/Onyxia/img/image5.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image5.png
rename to docs/Services/Onyxia/img/image5.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image6.png b/docs/Services/Onyxia/img/image6.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image6.png
rename to docs/Services/Onyxia/img/image6.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image7.png b/docs/Services/Onyxia/img/image7.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image7.png
rename to docs/Services/Onyxia/img/image7.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image8.png b/docs/Services/Onyxia/img/image8.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image8.png
rename to docs/Services/Onyxia/img/image8.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/image9.png b/docs/Services/Onyxia/img/image9.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/image9.png
rename to docs/Services/Onyxia/img/image9.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/minio.svg b/docs/Services/Onyxia/img/minio.svg
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/minio.svg
rename to docs/Services/Onyxia/img/minio.svg
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/onyxia-git-token.png b/docs/Services/Onyxia/img/onyxia-git-token.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/onyxia-git-token.png
rename to docs/Services/Onyxia/img/onyxia-git-token.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/onyxia-resources.png b/docs/Services/Onyxia/img/onyxia-resources.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/onyxia-resources.png
rename to docs/Services/Onyxia/img/onyxia-resources.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/rstudio-git-config.png b/docs/Services/Onyxia/img/rstudio-git-config.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/rstudio-git-config.png
rename to docs/Services/Onyxia/img/rstudio-git-config.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/secret-config.png b/docs/Services/Onyxia/img/secret-config.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/secret-config.png
rename to docs/Services/Onyxia/img/secret-config.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/secret.png b/docs/Services/Onyxia/img/secret.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/secret.png
rename to docs/Services/Onyxia/img/secret.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/secrettable.png b/docs/Services/Onyxia/img/secrettable.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/secrettable.png
rename to docs/Services/Onyxia/img/secrettable.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/toolbarsecret.png b/docs/Services/Onyxia/img/toolbarsecret.png
similarity index 100%
rename from docs/Services/pole-scientifique/Onyxia/docs/img/toolbarsecret.png
rename to docs/Services/Onyxia/img/toolbarsecret.png
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/index.md b/docs/Services/Onyxia/index.md
similarity index 98%
rename from docs/Services/pole-scientifique/Onyxia/docs/index.md
rename to docs/Services/Onyxia/index.md
index 7ad9921..b31c5fd 100644
--- a/docs/Services/pole-scientifique/Onyxia/docs/index.md
+++ b/docs/Services/Onyxia/index.md
@@ -1,487 +1,487 @@
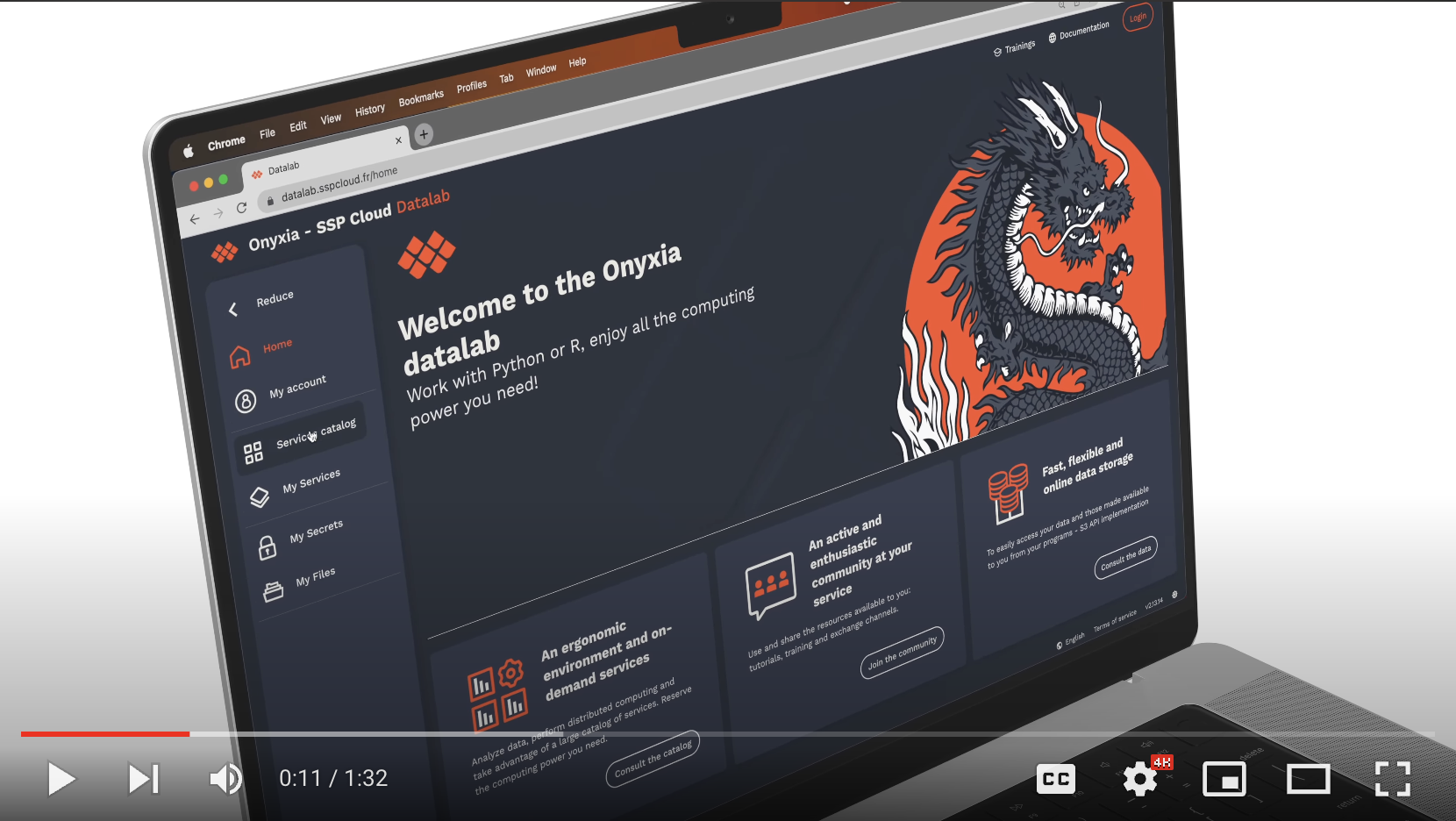
-# Qu’est-ce que le Datalab Onyxia du GENES ?
-
-Le datalab est une application web permettant d'accéder à un environnement de travail disposant de multiples services liés à la Data (Jupyter, RStudio, Mongodb, Kafka, Mlflow etc...) sans avoir à se préoccuper du déploiement de l’infrastructure.
-
-Au-delà de la simple facilitation d'accès aux outils de traitement de données modernes, le datalab promeut activement les bonnes pratiques en matière de traitement des données et de programmation, en favorisant la reproductibilité des résultats.
-
-Pour les élèves et chercheurs, le datalab est une opportunité unique d'autoformation. Grâce à son interface intuitive, les étudiants peuvent explorer, expérimenter et approfondir leurs compétences en temps réel, tout en s'adaptant aux standards actuels du monde professionnel.
-
-le datalab permet de travailler sur des environnements facilement reproductibles, grâces à l’enregistrement de la configuration des services et la capacité de paramétrer des scripts d’initialisation.
-
-Via le datalab, chaque utilisateur disposera d'un répertoire Git et d'un espace de stockage de type S3, qui seront automatiquement connectés à chaque service que l'utilisateur créera.
-
-L’utilisation de Git permet de synchroniser le projet local avec un serveur distant, rendant la perte de code quasi impossible. Il permet également de conserver un historique complet des choix et modifications effectuées sur le projet, favorisant ainsi le partage des modifications avec d'autres utilisateurs.
-
-En ce qui concerne la solution de stockage de fichiers S3, celle-ci est un système de stockage d'objets basé sur le cloud, compatible avec l'API S3 d'Amazon :
-
-- Les fichiers stockés sont facilement accessibles depuis n'importe quel endroit via une simple URL, pouvant être facilement partagée.
-- De plus, l'accès aux fichiers stockés est possible directement dans les services de data science (R, Python, etc.) proposés sur le Datalab, sans nécessiter de copie préalable des fichiers localement, améliorant ainsi considérablement la reproductibilité des analyses.
-L'avantage du datalab réside dans la possibilité de partager chaque service avec d'autres collaborateurs en un clic.
-
-## Les fonctionnalités du Datalab en bref :
-- Accès à un Catalogue de services déployable en libre-service
-
-- Les utilisateurs peuvent définir le nombre de RAM, CPU et GPU qu’ils souhaitent allouer à leurs services avec une limitation par utilisateur de : 5 services, 20 CPU, 50Go RAM, et 1 GPU. Ces limitations sont différentes concernant les groupes de projets.
-
-- Possibilité de faire des demandes auprès du DSIT du GENES pour ajouter de nouveaux services au catalogue selon vos besoins, nous contacter sois sur notre teams ici Datalab - GENES - Teams ou via notre mail support à l’adresse support.informatique@ensae.fr.
-
-- Capacité de partager l'accès à vos services et ressources du datalab avec un groupe de personnes.
-
-- Possibilité de spécifier un script init personnalisable exécuté au lancement des services, plus de détails ici.
-
-- Enregistrer, restaurer et partager la configuration de vos services avec vos collaborateurs, plus de détails ici.
-
-- Intégration de secrets sous forme de variables d'environnement dans les services du Datalab, permettant de stocker les informations sensibles de type clés d'API dans Vault et de les rendre accessibles dans les services sous forme de variable. (à rajouter lien vers guide)
-
-- Possibilités d’accéder et de créé des formations techniques sur différents outils mis à disposition pour vos collaborateurs ou élèves. Cette fonctionnalités sera ajoutée sous peu, dans le cas d'un enseignant par exemple, vous pourrez ajouter une formation/cours sur un sujet. Y ajouter des URLs de configuration de services, sur lequels les élèves pourront cliquées et qui déploiera automatiquement des services sur leurs interface Onyxia sur lequels ils pourront travailler/faire des exercices dans un environnements que vous avez entièrement paramétré. Cette méthode permet ainsi aux élèves d'avoir accès à un environnement stable et reproductibles instantanément. Le datalab Onyxia de l'Insee possède cette fonctionnalités qui est visible ici.
-
-
-
-## Présentation rapide du datalab en vidéo :
-
-
-  -
-
-
-
-## FAQ
-
-
-## Liens utiles
- - Gestion des secrets
- - Stockages de données
- - Contrôle de version
- - Conditions général d'utilisations
-
-
-
-# Une plateforme de mutualisation
-Le projet du datalab part du constat de difficultés communes rencontrées par les datascientists du secteur public :
-
-- des agents souvent isolés, du fait de la relative rareté des compétences data dans l'administration ;
-- des infrastructures inadaptées, aussi bien en matière de ressources que de technologies, qui constituent un frein à l'innovation ;
-- une difficulté à passer de l'expérimentation à la mise en production, du fait de multiples séparations (séparation physique, langage de développement, modes de travail) entre les directions métier et la production informatique.
-
-Face à ce constat, le Datalab a été construit pour proposer une plateforme de mutualisation à plusieurs niveaux
-
-- partage d'une infrastructure moderne, centrée autour du déploiement de services via des conteneurs, et dimensionnée pour les usages de data science ;
-- partage de méthodes, via une mutualisation des services de data science proposés, auxquels chacun peut contribuer ;
-- partage de connaissances, via des formations associées au Datalab ainsi que la constitution de commaunautés d'entraide centrées sur son utilisation.
-
-!!! info
- Onyxia, Datalab du Genes: quelles différences ?
-
- [Onyxia ](https://github.com/InseeFrLab/onyxia.git)est un projet open-source de l'Insee qui propose une plateforme de services de _data science_, accessible via une application Web. Le [Datalab du Genes](https://onyxia.lab.groupe-genes.fr/) est une instance du projet Onyxia, hébergée au GENES.
-
-
-# Principes fondamentaux
-
-L'architecture du Datalab est basée sur un ensemble de principes fondamentaux :
-
-- une production orientée data science, en proposant une infrastructure dimensionnée à la plupart des usages et un catalogue de services couvrant l'ensemble du cycle de vie des projets data ;
-- des choix qui favorisent l'autonomie des usagers, en évitant tout enfermement propriétaire et en permettant l'accès aux couches basses de l'infrastructure pour couvrir les besoins avancés et spécifiques ;
-- un projet 100% cloud-natif, mais également cloud-agnostique, permettant un déploiement simple sur n'importe quelle infrastructure ;
-- un projet complètement open-source, à la fois du point de vue de ses briques constitutives que de sa diffusion (licence MIT).
-
-# Offre de services
-Le Datalab est accessible via une Interface utilisateur moderne et réactive, centrée sur l'expérience utilisateur. Celle-ci constitue le liant technique entre les différentes composantes du datalab :
-
-- des technologies open-source qui constituent l'état de l'art du déploiement et de l'orchestration de conteneurs, du stockage et de la sécurité ;
-- un catalogue de services et d'outils pour accompagner les projets de data science ;
-- une plateforme de formation et de documentation pour faciliter l'onboarding sur les technologies proposées.
-
-
-
-
-
-
-## FAQ
-
-
-## Liens utiles
- - Gestion des secrets
- - Stockages de données
- - Contrôle de version
- - Conditions général d'utilisations
-
-
-
-# Une plateforme de mutualisation
-Le projet du datalab part du constat de difficultés communes rencontrées par les datascientists du secteur public :
-
-- des agents souvent isolés, du fait de la relative rareté des compétences data dans l'administration ;
-- des infrastructures inadaptées, aussi bien en matière de ressources que de technologies, qui constituent un frein à l'innovation ;
-- une difficulté à passer de l'expérimentation à la mise en production, du fait de multiples séparations (séparation physique, langage de développement, modes de travail) entre les directions métier et la production informatique.
-
-Face à ce constat, le Datalab a été construit pour proposer une plateforme de mutualisation à plusieurs niveaux
-
-- partage d'une infrastructure moderne, centrée autour du déploiement de services via des conteneurs, et dimensionnée pour les usages de data science ;
-- partage de méthodes, via une mutualisation des services de data science proposés, auxquels chacun peut contribuer ;
-- partage de connaissances, via des formations associées au Datalab ainsi que la constitution de commaunautés d'entraide centrées sur son utilisation.
-
-!!! info
- Onyxia, Datalab du Genes: quelles différences ?
-
- [Onyxia ](https://github.com/InseeFrLab/onyxia.git)est un projet open-source de l'Insee qui propose une plateforme de services de _data science_, accessible via une application Web. Le [Datalab du Genes](https://onyxia.lab.groupe-genes.fr/) est une instance du projet Onyxia, hébergée au GENES.
-
-
-# Principes fondamentaux
-
-L'architecture du Datalab est basée sur un ensemble de principes fondamentaux :
-
-- une production orientée data science, en proposant une infrastructure dimensionnée à la plupart des usages et un catalogue de services couvrant l'ensemble du cycle de vie des projets data ;
-- des choix qui favorisent l'autonomie des usagers, en évitant tout enfermement propriétaire et en permettant l'accès aux couches basses de l'infrastructure pour couvrir les besoins avancés et spécifiques ;
-- un projet 100% cloud-natif, mais également cloud-agnostique, permettant un déploiement simple sur n'importe quelle infrastructure ;
-- un projet complètement open-source, à la fois du point de vue de ses briques constitutives que de sa diffusion (licence MIT).
-
-# Offre de services
-Le Datalab est accessible via une Interface utilisateur moderne et réactive, centrée sur l'expérience utilisateur. Celle-ci constitue le liant technique entre les différentes composantes du datalab :
-
-- des technologies open-source qui constituent l'état de l'art du déploiement et de l'orchestration de conteneurs, du stockage et de la sécurité ;
-- un catalogue de services et d'outils pour accompagner les projets de data science ;
-- une plateforme de formation et de documentation pour faciliter l'onboarding sur les technologies proposées.
-
-Briques fondamentales du Datalab
-
-
-
-

-
Un catalogue de services complet pour les projets de data science
-
-
-

-
Briques fondamentales du Datalab
+
+
+
+
+
Un catalogue de services complet pour les projets de data science
+
+
+
+
Configuration recommandée pour la génération d’un jeton d’accès GitHub
- 
-
-=== "GitGenes"
- Rendez vous sur directement sur le lien: https://code.groupe-genes.fr/user/settings/applications
- Vous retrouverez un block "Générer un nouveau jeton", vous devrez:
- - Ajouter un nom au jeton
- - Spécifier si le token peu accéder soit à vos dépôts publique uniquement ou tout (public, privé et limité)
- - Sélectionner les autorisations liées au token
- 
-
- Voici la configuration recommandée pour la génération d’un jeton d’accès GitGenes (modifier l'accès uniquement au "repository"):
- 
-
-
-
-Une fois le jeton généré, ce dernier apparaît à l'écran. Un jeton ne peut être visualisé qu'une seule fois ; en cas de perte, il faudra en générer un nouveau.
-
-### Création & récupération de l'URL d'un dépôt
-
-L'URL de vos dépôt vous sera demander lors de la configuration de vos service du datalab, celui-ci doit être spécifié afin que le service clone automatiquement votre dépôt sur votre service.
-
-
-=== "Github"
-
- Rendez vous sur Github, cliquer en haut à droite sur l'image de votre profile et sélectionner "Your repositories"
- 
-
- Ici vous retrouver tous vos dépôts et pourrez en créer de nouveau en cliquant sur l'icône verte "new".
-
- Pour récuperer l'URL, cliquer sur le dépôts que vous souhaitez cloner sur vos services du datalab vu précédemment. Sur la nouvelle page, cliquer sur le menu déroulant vert "<> code" puis copier l'URL https:
- 
-
-
-=== "GitGenes"
- Pour la création d'un dépôt, rendez vous sur GitGenes, cliquer en haut à droite sur l'icône "+" puis "Nouveau dépôt"
- 
-
- Pour la création d'un dépôt, rendez vous sur GitGenes, cliquer en haut à droite sur l'image de votre profile puis sur "Profil":
- 
-
- Ici vous retrouverez vos différents dépôt personnel, cliquer sur le dépôt que vous souhaitez cloner sur vos services du datalab, sur la nouvelle page cliquer sur "copier l'URL" HTTPS:
- 
-
-
-
-### Ajouter les informations Git sur le Datalab
-Nous avons vu précédemment les différentes informations nécessaires pour la configuration d'un dépôt GitHub & GitGenes sur le datalab. Nous allons maintenant voir où ajouter ces informations sur le datalab pour que vos dépôt soient clonés automatiquement sur vos services du datalab.
-
-#### Nom d'utilisateur, email & jeton d'accès (token)
-
-Ces informations peuvent être ajoutées à deux endroits différents:
- - Sur l'onglet "Mon compte" qui va permettre d'ajouter un Git qui sera ensuite configuré par défaut sur chaque nouveau service que vous créerez, plus d'information ici.
- - Individuellement sur chaques services que vous créerez dans le sous onglet "Git" lors de la configuration du service, plus d'information ici.
-
-
-#### Ajout de l'URL de dépôt
-
-Pour que vos dépôt soit ajouter sur vos services, il faudra le spécifié l'URL de dépôt à chaque création d'un nouveau service L'URL de dépôt détaillé ici, penser donc à enregistrer la configuration de vos services afin de facilité la création récurente de vos services, plus de détails sur comment enregistrer et configurer un service ici.
-
-
-### Git via le terminal
-
-Le jeton d'accès GitHub est disponible dans le terminal des différents services via la variable d'environnement `$GIT_PERSONAL_ACCESS_TOKEN`. Afin d'éviter de devoir s'authentifier à chaque opération impliquant le dépôt distant (_clone_, _push_ & _pull_), il est recommandé de cloner celui-ci en incluant le jeton d'accès dans le lien HTTPS, à l'aide de la commande suivante :
-```git
- git clone https://${GIT_PERSONAL_ACCESS_TOKEN}@github.com//.git
-```
-où \ et \ sont à remplacer respectivement par le nom d'utilisateur et le nom du dépôt GitHub.
-
-### Git via des interfaces graphiques intégrées
-
-Les principaux services de production de code disponibles sur le Datalab disposent d'une interface graphique pour faciliter l'utilisation de Git :
-
-* RStudio : RStudio propose une interface graphique pour Git native et assez complète. La documentation utilitR présente son fonctionnement en détail ;
-* Jupyter : le plugin jupyterlab-git permet un interfaçage (assez sommaire) de Jupyter avec Git ;
-* VSCode : VSCode propose nativement une interface graphique très bien intégrée avec Git et GitHub. Une documentation détaillée(en Anglais) présente les possibilités de l'outil.
-
-!!! warning
+# Contrôle de version
+
+## Pourquoi utiliser le contrôle de version ?
+
+Le Datalab est une plateforme mutualisée : les ressources utilisées par les services sont partagées entre les différents utilisateurs. A ce titre, les services du Datalab fonctionnent sur le modèle des conteneurs éphémères : dans un usage standard, l'utilisateur lance un service, réalise des traitements de données, sauvegarde le code qui a permis de réaliser ces traitements, et supprime l'instance du service. Cette sauvegarde du code est grandement facilitée par l'usage du contrôle de version.
+
+Cette considération de performance ne doit cependant pas être vue comme une contrainte : le contrôle de version est une bonne pratique essentielle de développement. Les bénéfices sont nombreux, aussi bien à titre individuel :
+
+* le projet local est synchronisé avec un serveur distant, rendant la perte de code quasi impossible ;
+* l'historique complet des choix et modifications effectuées sur le projet est conservé ;
+* l'utilisateur peut parcourir cet historique pour rechercher les modifications qui ont pu créer des erreurs, et décider à tout moment de revenir à une version précédente du projet, ou bien de certains fichiers.
+
+Dans le cadre de projets collaboratifs :
+
+* le travail simultané sur un même projet est possible, sans risque de perte ;
+* l'utilisateur peut partager ses modifications tout en bénéficiant de celles des autres ;
+* il devient possible de contribuer à des projets open-source, pour lesquels l'usage de Git est très largement standard.
+
+!!! warning
+ Ce tutoriel vise à présenter comment le contrôle de version peut être facilement implémenté grâce aux outils présents sur le Datalab. Il ne présente pas le fonctionnement de Git et présuppose donc une certaine familiarité avec l'outil. De nombreuses ressources en ligne peuvent servir d'introduction ; l'utilisateur de R pourra par exemple consulter ce guide. Une formation complète à Git sera bientôt proposée dans l'espace formation du Datalab qui sera bientôt ajouter sur notre Datalab Onyxia.
+
+
+## Intégration de Git avec le Datalab
+
+### Pourquoi Git ?
+
+Bien qu'une utilisation hors-ligne de Git soit possible, tout l'intérêt du contrôle de version réside dans la synchronisation de la copie locale d'un projet (_clone_) avec un dépôt distant (_remote_). Différents services de forge logicielle permettent cette synchronisation des projets Git, dont les plus connus sont Github et GitLab. Dans la mesure où le premier dispose aujourd'hui de beaucoup plus de visibilité — par exemple, les dépôts du Genes, sont hébergé en interne via Gitea accessible ici.
+
+Vous disposer donc automatiquement d'un dépôt GitGenes, que vous pouvez accéder en utilisant votre compte ENSAE. Celui-ci est également automatiquement intégré sur votre compte du datalab comme décrit ici.
+
+
+le Datalab propose une intégration facilitée avec Git, que nous vous présentons à travers ce tutoriel. La suite du guide vous permettra de configurer GitHub & GitGenes sur le datalab à deux endroits:
+ - Dans l'onglet Services externes qui ajoutera la configuration de votre dépôt git automatiquement sur chaques service qui vous créé (plus d'information sur notre guide principal ici )
+ - Lors de la création d'un Services
+
+Le guide montre en détail comment récupérer les informations suivantes sur Github & GitGenes:
+ - Nom d'utilisateur pour Git
+ - Email pour Git
+ - Jeton d'accès personnel (Token)
+ - URL Repository
+
+
+!!! tip
+ La suite du tutoriel nécessite de disposer d'un compte GitHub ou GitGenes.
+
+
+!!! info
+ Si l'utilisation du Datalab avec la plateforme GitHub & GitGenes est facilitée, elle n'est en aucun cas obligatoire : il reste tout à fait possible d'utiliser la forge logicielle de son choix pour la synchronisation des projets.
+
+
+### Récuperer votre nom d'utilisateur et email
+
+
+
+=== "Github"
+
+ Votre nom d'utilisateur et email sont directement récupérable sur ce lien (paramètres utilisateur puis "Email").
+
+ 
+
+
+=== "GitGenes"
+ Vous retrouverez automatiquement votre nom d'utilisateur dans votre compte GitGenes disponible ici (paramètres utilisateur).
+ 
+
+ Votre nom d'utilisateur sera systématiquement composé tout attaché de la première lettre de votre prénom + votre nom + "-ensae" exemple:
+ - Nom: Houdin ; Prenom: Christophe
+ - Nom d'utilisateur: hchristophe-ensae
+
+
+### Créer un jeton d'accès (_token_)
+
+Le jeton d'accès n'est affiché q'une seul fois après sa création et n'est plus récupérable par la suite. Si vous perdez votre token vous devrer simplement en recréé un :
+
+=== "Github"
+
+ La synchronisation avec un dépôt distant nécessite une authentification auprès de GitHub. Celle-ci s'effectue à l'aide d'un jeton d'accès personnel, qui doit être généré à partir du compte GitHub de l'utilisateur. Le service de génération est accessible à cette adresse. La documentation GitHub(en Anglais) propose des illustrations pour guider le processus.
+
+
+ Pour générer un jeton, il est nécessaire de choisir un nom de jeton, un délai d'expiration et des droits d'accès (_scope_). Il est recommandé de choisir un délai court (30 jours) et un accès restreint (_repo_ seulement) afin de limiter les risques de sécurité en cas de diffusion malveillante du jeton.
+
+ Configuration recommandée pour la génération d’un jeton d’accès GitHub
+ 
+
+=== "GitGenes"
+ Rendez vous sur directement sur le lien: https://code.groupe-genes.fr/user/settings/applications
+ Vous retrouverez un block "Générer un nouveau jeton", vous devrez:
+ - Ajouter un nom au jeton
+ - Spécifier si le token peu accéder soit à vos dépôts publique uniquement ou tout (public, privé et limité)
+ - Sélectionner les autorisations liées au token
+ 
+
+ Voici la configuration recommandée pour la génération d’un jeton d’accès GitGenes (modifier l'accès uniquement au "repository"):
+ 
+
+
+
+Une fois le jeton généré, ce dernier apparaît à l'écran. Un jeton ne peut être visualisé qu'une seule fois ; en cas de perte, il faudra en générer un nouveau.
+
+### Création & récupération de l'URL d'un dépôt
+
+L'URL de vos dépôt vous sera demander lors de la configuration de vos service du datalab, celui-ci doit être spécifié afin que le service clone automatiquement votre dépôt sur votre service.
+
+
+=== "Github"
+
+ Rendez vous sur Github, cliquer en haut à droite sur l'image de votre profile et sélectionner "Your repositories"
+ 
+
+ Ici vous retrouver tous vos dépôts et pourrez en créer de nouveau en cliquant sur l'icône verte "new".
+
+ Pour récuperer l'URL, cliquer sur le dépôts que vous souhaitez cloner sur vos services du datalab vu précédemment. Sur la nouvelle page, cliquer sur le menu déroulant vert "<> code" puis copier l'URL https:
+ 
+
+
+=== "GitGenes"
+ Pour la création d'un dépôt, rendez vous sur GitGenes, cliquer en haut à droite sur l'icône "+" puis "Nouveau dépôt"
+ 
+
+ Pour la création d'un dépôt, rendez vous sur GitGenes, cliquer en haut à droite sur l'image de votre profile puis sur "Profil":
+ 
+
+ Ici vous retrouverez vos différents dépôt personnel, cliquer sur le dépôt que vous souhaitez cloner sur vos services du datalab, sur la nouvelle page cliquer sur "copier l'URL" HTTPS:
+ 
+
+
+
+### Ajouter les informations Git sur le Datalab
+Nous avons vu précédemment les différentes informations nécessaires pour la configuration d'un dépôt GitHub & GitGenes sur le datalab. Nous allons maintenant voir où ajouter ces informations sur le datalab pour que vos dépôt soient clonés automatiquement sur vos services du datalab.
+
+#### Nom d'utilisateur, email & jeton d'accès (token)
+
+Ces informations peuvent être ajoutées à deux endroits différents:
+ - Sur l'onglet "Mon compte" qui va permettre d'ajouter un Git qui sera ensuite configuré par défaut sur chaque nouveau service que vous créerez, plus d'information ici.
+ - Individuellement sur chaques services que vous créerez dans le sous onglet "Git" lors de la configuration du service, plus d'information ici.
+
+
+#### Ajout de l'URL de dépôt
+
+Pour que vos dépôt soit ajouter sur vos services, il faudra le spécifié l'URL de dépôt à chaque création d'un nouveau service L'URL de dépôt détaillé ici, penser donc à enregistrer la configuration de vos services afin de facilité la création récurente de vos services, plus de détails sur comment enregistrer et configurer un service ici.
+
+
+### Git via le terminal
+
+Le jeton d'accès GitHub est disponible dans le terminal des différents services via la variable d'environnement `$GIT_PERSONAL_ACCESS_TOKEN`. Afin d'éviter de devoir s'authentifier à chaque opération impliquant le dépôt distant (_clone_, _push_ & _pull_), il est recommandé de cloner celui-ci en incluant le jeton d'accès dans le lien HTTPS, à l'aide de la commande suivante :
+```git
+ git clone https://${GIT_PERSONAL_ACCESS_TOKEN}@github.com//.git
+```
+où \ et \ sont à remplacer respectivement par le nom d'utilisateur et le nom du dépôt GitHub.
+
+### Git via des interfaces graphiques intégrées
+
+Les principaux services de production de code disponibles sur le Datalab disposent d'une interface graphique pour faciliter l'utilisation de Git :
+
+* RStudio : RStudio propose une interface graphique pour Git native et assez complète. La documentation utilitR présente son fonctionnement en détail ;
+* Jupyter : le plugin jupyterlab-git permet un interfaçage (assez sommaire) de Jupyter avec Git ;
+* VSCode : VSCode propose nativement une interface graphique très bien intégrée avec Git et GitHub. Une documentation détaillée(en Anglais) présente les possibilités de l'outil.
+
+!!! warning
Les interfaces graphiques facilitent la prise en main de Git, mais ne remplacent jamais complètement l'usage de l'outil via un terminal du fait d'une intégration nécessairement imparfaite. Il est donc utile de se familiariser avec l'usage de Git via le terminal le plus tôt possible.
\ No newline at end of file
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/Image28.png b/docs/Services/pole-scientifique/Onyxia/docs/img/Image28.png
deleted file mode 100644
index d3ff099..0000000
Binary files a/docs/Services/pole-scientifique/Onyxia/docs/img/Image28.png and /dev/null differ
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/Image29.png b/docs/Services/pole-scientifique/Onyxia/docs/img/Image29.png
deleted file mode 100644
index aefd00f..0000000
Binary files a/docs/Services/pole-scientifique/Onyxia/docs/img/Image29.png and /dev/null differ
diff --git a/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes.PNG b/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes.PNG
deleted file mode 100644
index 36d452d..0000000
Binary files a/docs/Services/pole-scientifique/Onyxia/docs/img/git-genes.PNG and /dev/null differ