41 KiB
Qu’est-ce que le Datalab Onyxia du GENES ?
Le datalab est une application web permettant d'accéder à un environnement de travail disposant de multiples services liés à la Data (Jupyter, RStudio, Mongodb, Kafka, Mlflow etc...) sans avoir à se préoccuper du déploiement de l’infrastructure.
Au-delà de la simple facilitation d'accès aux outils de traitement de données modernes, le datalab promeut activement les bonnes pratiques en matière de traitement des données et de programmation, en favorisant la reproductibilité des résultats.
Pour les élèves et chercheurs, le datalab est une opportunité unique d'autoformation. Grâce à son interface intuitive, les étudiants peuvent explorer, expérimenter et approfondir leurs compétences en temps réel, tout en s'adaptant aux standards actuels du monde professionnel.
le datalab permet de travailler sur des environnements facilement reproductibles, grâces à l’enregistrement de la configuration des services et la capacité de paramétrer des scripts d’initialisation.
Via le datalab, chaque utilisateur disposera d'un répertoire Git et d'un espace de stockage de type S3, qui seront automatiquement connectés à chaque service que l'utilisateur créera.
L’utilisation de Git permet de synchroniser le projet local avec un serveur distant, rendant la perte de code quasi impossible. Il permet également de conserver un historique complet des choix et modifications effectuées sur le projet, favorisant ainsi le partage des modifications avec d'autres utilisateurs.
En ce qui concerne la solution de stockage de fichiers S3, celle-ci est un système de stockage d'objets basé sur le cloud, compatible avec l'API S3 d'Amazon :
- Les fichiers stockés sont facilement accessibles depuis n'importe quel endroit via une simple URL, pouvant être facilement partagée.
- De plus, l'accès aux fichiers stockés est possible directement dans les services de data science (R, Python, etc.) proposés sur le Datalab, sans nécessiter de copie préalable des fichiers localement, améliorant ainsi considérablement la reproductibilité des analyses. L'avantage du datalab réside dans la possibilité de partager chaque service avec d'autres collaborateurs en un clic.
Les fonctionnalités du Datalab en bref :
-
Accès à un Catalogue de services déployable en libre-service
-
Les utilisateurs peuvent définir le nombre de RAM, CPU et GPU qu’ils souhaitent allouer à leurs services avec une limitation par utilisateur de : 5 services, 20 CPU, 50Go RAM, et 1 GPU. Ces limitations sont différentes concernant les groupes de projets.
-
Possibilité de faire des demandes auprès du DSIT du GENES pour ajouter de nouveaux services au catalogue selon vos besoins, nous contacter sois sur notre teams ici Datalab - GENES - Teams ou via notre mail support à l’adresse support.informatique@ensae.fr.
-
Capacité de partager l'accès à vos services et ressources du datalab avec un groupe de personnes.
-
Possibilité de spécifier un script init personnalisable exécuté au lancement des services, plus de détails ici.
-
Enregistrer, restaurer et partager la configuration de vos services avec vos collaborateurs, plus de détails ici.
-
Intégration de secrets sous forme de variables d'environnement dans les services du Datalab, permettant de stocker les informations sensibles de type clés d'API dans Vault et de les rendre accessibles dans les services sous forme de variable. (à rajouter lien vers guide)
-
Possibilités d’accéder et de créé des formations techniques sur différents outils mis à disposition pour vos collaborateurs ou élèves. Cette fonctionnalités sera ajoutée sous peu, dans le cas d'un enseignant par exemple, vous pourrez ajouter une formation/cours sur un sujet. Y ajouter des URLs de configuration de services, sur lequels les élèves pourront cliquées et qui déploiera automatiquement des services sur leurs interface Onyxia sur lequels ils pourront travailler/faire des exercices dans un environnements que vous avez entièrement paramétré. Cette méthode permet ainsi aux élèves d'avoir accès à un environnement stable et reproductibles instantanément. Le datalab Onyxia de l'Insee possède cette fonctionnalités qui est visible ici.
Présentation rapide du datalab en vidéo :
FAQ
Liens utiles
Une plateforme de mutualisation
Le projet du datalab part du constat de difficultés communes rencontrées par les datascientists du secteur public :
- des agents souvent isolés, du fait de la relative rareté des compétences data dans l'administration ;
- des infrastructures inadaptées, aussi bien en matière de ressources que de technologies, qui constituent un frein à l'innovation ;
- une difficulté à passer de l'expérimentation à la mise en production, du fait de multiples séparations (séparation physique, langage de développement, modes de travail) entre les directions métier et la production informatique.
Face à ce constat, le Datalab a été construit pour proposer une plateforme de mutualisation à plusieurs niveaux
- partage d'une infrastructure moderne, centrée autour du déploiement de services via des conteneurs, et dimensionnée pour les usages de data science ;
- partage de méthodes, via une mutualisation des services de data science proposés, auxquels chacun peut contribuer ;
- partage de connaissances, via des formations associées au Datalab ainsi que la constitution de commaunautés d'entraide centrées sur son utilisation.
!!! info Onyxia, Datalab du Genes: quelles différences ?
[Onyxia ](https://github.com/InseeFrLab/onyxia.git)est un projet open-source de l'Insee qui propose une plateforme de services de _data science_, accessible via une application Web. Le [Datalab du Genes](https://onyxia.lab.groupe-genes.fr/) est une instance du projet Onyxia, hébergée au GENES.
Principes fondamentaux
L'architecture du Datalab est basée sur un ensemble de principes fondamentaux :
- une production orientée data science, en proposant une infrastructure dimensionnée à la plupart des usages et un catalogue de services couvrant l'ensemble du cycle de vie des projets data ;
- des choix qui favorisent l'autonomie des usagers, en évitant tout enfermement propriétaire et en permettant l'accès aux couches basses de l'infrastructure pour couvrir les besoins avancés et spécifiques ;
- un projet 100% cloud-natif, mais également cloud-agnostique, permettant un déploiement simple sur n'importe quelle infrastructure ;
- un projet complètement open-source, à la fois du point de vue de ses briques constitutives que de sa diffusion (licence MIT).
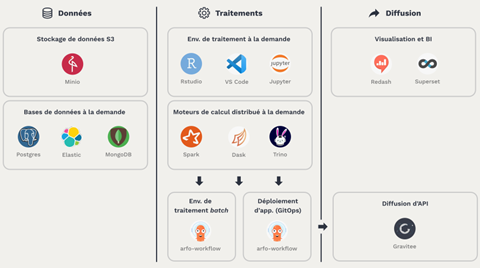
Offre de services
Le Datalab est accessible via une Interface utilisateur moderne et réactive, centrée sur l'expérience utilisateur. Celle-ci constitue le liant technique entre les différentes composantes du datalab :
- des technologies open-source qui constituent l'état de l'art du déploiement et de l'orchestration de conteneurs, du stockage et de la sécurité ;
- un catalogue de services et d'outils pour accompagner les projets de data science ;
- une plateforme de formation et de documentation pour faciliter l'onboarding sur les technologies proposées.

Le catalogue de services est pensé de manière à accommoder l'essentiel des usages des data scientists, du développement en self-service à la mise en production de traitements ou d'application. L'ensemble du cycle de vie d'un projet data est ainsi couvert, et le catalogue des services est régulièrement étendu pour répondre aux nouveaux besoins des utilisateurs.
Un projet ouvert
Le projet du Datalab est résolument ouvert, à de multiples niveaux :
- le Datalab est accessible via son interface Web à tous les agents du service public ainsi qu'aux élèves des écoles de statistique liées à l'Ensae (Cepe, Ensai, Ensae) ;
- le code source ouvert et la modularité du projet rendent possible le déploiement d'une instance du datalab personnalisée sur n'importe quelle infrastructure basée sur un cluster Kubernetes ;
- le projet est ouvert aux contributions extérieures, qu'elles concernent le catalogue des services, l'interface graphique ou l'agencement des briques logicielles qui le constituent.
Première utilisation
Visite guidée du Datalab
Bienvenue sur le Datalab, plateforme de libre service mutualisée de traitement de données, destinée aux statisticiens et data scientists de l'Etat. Ce tutoriel propose une visite guidée du Datalab pour être rapidement opérationnel dans l'utilisation de ses services.
Il s’agit d’une présentation sommaire n'expliquant pas de façon détaillé chaques paramétrages possible, ceux-ci sont expliqués point par point plus plus tard dans ce guide. Voici quelques liens de redirection vers les parties détaillées: - Mon compte - Catalogue de services - Mes services - Mes secrets - Mes fichiers
!!! warning Les conditions d'utilisation du Datalab sont consultables à ici. Nous rappelons que le Datalab est destiné exclusivement au traitement de données publiques et non-sensibles. Des projets d'expérimentation mobilisant des données non ouvertes peuvent être menés en concertation avec l'équipe du Datalab, sous réserve de se conformer aux règles de sécurité spécifiques au projet.
Le catalogue de services
Le catalogue de services est au centre de l'utilisation du Datalab. Il propose un ensemble de services destinés aux traitements statistiques de données ainsi qu'à la gestion complète des projets de data science.

Lancer un service
Pour lancer un service, il suffit de cliquer sur le bouton Lancer du service désiré.

Une page centrée sur le service demandé s'ouvre alors, qui offre plusieurs possibilités :
-
cliquer à nouveau sur le bouton
Lancerpour lancer le service avec sa configuration par défaut ; -
personnaliser le nom que portera l'instance une fois le service lancé, Attention, si vous enregistrer la configuration d’un service et que celui-ci a le même nom d’un service que vous avez déjà enregistré, sa configuration sera écrasée ;
-
dérouler un menu de configuration afin de personnaliser la configuration du service avant de le lancer ;
-
sauvegarder une configuration personnalisée en cliquant sur le signet en haut à droite du service, ce qui vous permettra d’enregistrer l'entièreté de la configuration du service et de le relancer depuis l’onglet Mes services.
La configuration précise de S3, Kubernetes, Init etc... sur les services constitue un usage avancé, chaque onglet du site web seront expliqués en détails plus loin à la section Configuration avancée du Catalogue de services.
Utiliser un service
L'action de lancer un service amène automatiquement sur la page Mes services, où sont listées toutes les instances en activité sur le compte de l'utilisateur.

Une fois le service lancé, un bouton Ouvrir apparaît qui permet l'accès au service. Un mot de passe et, selon les services, un nom d'utilisateur est généralement requis pour pouvoir utiliser le service. Ces informations sont disponibles dans le README associé au service, auquel on accède en cliquant sur le bouton du même nom.
Supprimer une instance
Supprimer une instance d'un service s'effectue simplement en cliquant sur l'icône en forme de poubelle en dessous de l'instance.
!!! danger
Pour certains services, la suppression d'une instance entraîne la suppression de toutes les données associées, et cette action est irrémédiable. Il est donc nécessaire de toujours bien lire le README associé à l'instance, qui précise les conséquences d'une suppression de l'instance. De manière générale, il est très important de s'assurer que les données ainsi que le code utilisés sont sauvegardés avant de supprimer l'instance. L'idéal est de versionner son code avec Git et de procéder à des sauvegardes régulières des données à l'aide du système de stockage S3.
!!! info Les ressources mises à disposition pour l'execution des services sont partagées entre les différents utilisateurs du Datalab. Veuillez à ne pas laisser en cours des services dont vous ne faites plus l'usage. Nous procédons parfois à une suppression systématique des instances inactives depuis un certain temps, afin de libérer des ressources.
Partager un service
Il est possible de partager un service à un groupe de personnes en cochant la case "Partager le service" à l'ouverture du service. Les autres membres du groupe verront le service et pourront l'utiliser. La création de groupes se fait en écrivant aux administrateurs sur Teams ou par mail à l'adresse support.informatique@ensae.fr.
Pour un besoin ponctuel, il est aussi possible de partager un service que l'on a créé à une autre personne, Attention via cette méthode, une seule personne à la fois peut se connecter à un service.
Il vous suffira donc de lui communiquer l'URL lors ce que vous êtes sur votre service (type https://user-aaaaaaaaaaaaaa-xxxxxxx-x.lab.groupe-genes.fr/):

Ainsi que le mot de passe du service, qui est configurable et récupérable de différentes manières, lors de la création du service dans le sous onglet “Security”:
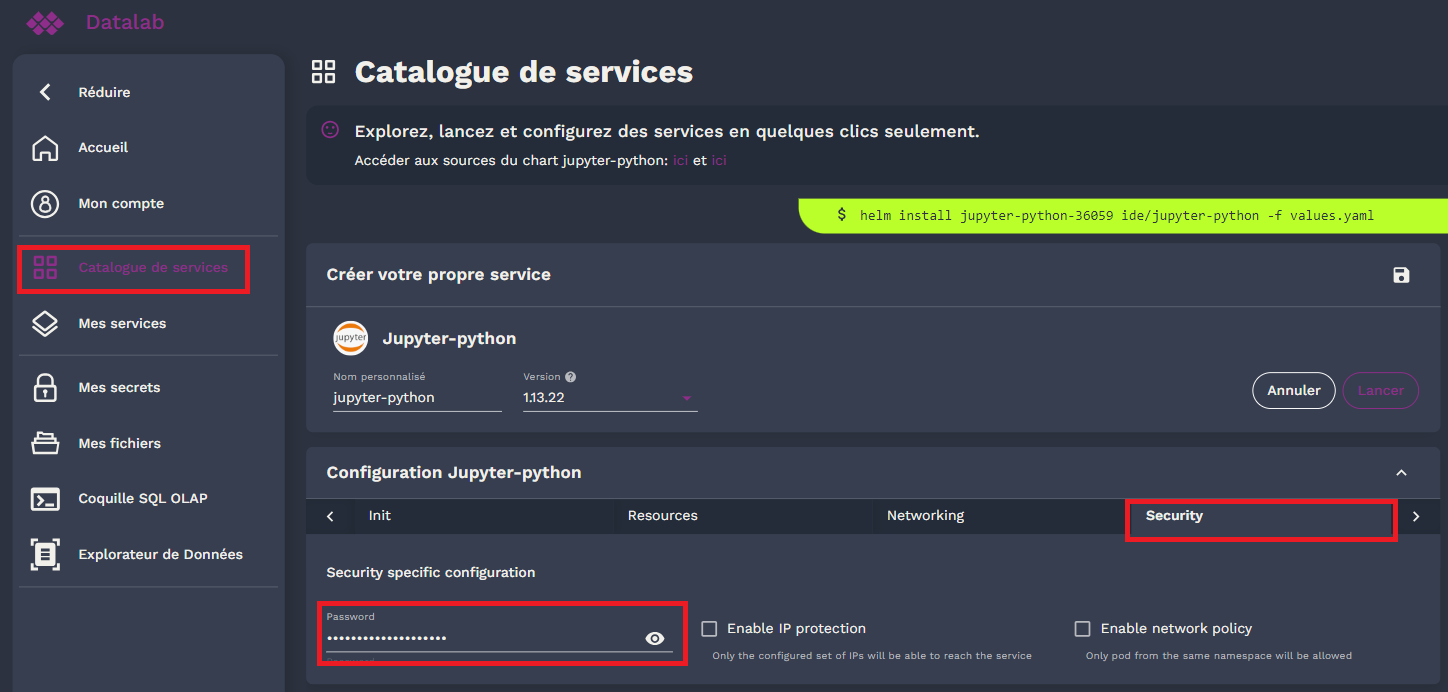
Cependant attention, car par défaut lors de la configuration d’un service, le mot de passe sera toujours le mêmes et qui a été spécifié dans l’onglet Mon compte puis Information du compte:

Si vous ne vous rappelez plus du mot de passe que vous avez attribué lors de la configuration d’un service, celui-ci est affiché automatiquement à chaque fois que vous re-lancer votre service via l’onglet Mes services:

La meilleure pratique est donc, pour un service que vous souhaitez partager directement en fournissant l’URL du service, de modifier le mot de passe par défaut lors de la création du service comme vu précédemment dans le sous onglet “Security”.
Le nom d'utilisateur reste Onyxia. Par ailleurs il ne faut pas cocher Enable IP protection et Enable network policy dans l'onglet “Security”, par défaut elles ne sont pas cochées. Pour rappel, via cette méthode une seule personne à la fois peut se connecter à un service.
Groupe de projet
Lors ce que vous êtes affectés à un groupe de projet, en haut à gauche de l'interface d'Onyxia vous aurez un mini-menu déroulant "Projet" où vous aurez la possibilité de choisir les projets auquels vous êtes affectés ou votre espace personnel.
Cela vous permettra de choisir les ressources auxquels vous souhaitez accéder, celle liées à votre groupe de projet ou vos ressources personnels. Cette option est visible uniquement si vous avez accès à un groupe de projet.

Lors ce que vous avez sélectionné un projet, vous verrez uniquement les ressources liées à celui-ci et ne verrez pas les ressources de votre espace personnel, cela concerne les onglets "Mes Services, Mes Fichiers et Mes Secrets":

Mon compte
Dans cet onglet vous pourrez modifier différents paramètres, les plus important étant :
-
Modification des comptes et jetons Gitlab, Github et Kaggle qui seront par lié par défaut a tous les services que vous créérez, disponible dans le sous onglet Services externes ;
-
La capacité de récupérer des scripts d’initialisation dans le language de programmation de votre choix, qui vous permettrons d’accéder au stockage S3 en dehors des services du datalab Onyxia GENES. Disponible dans le sous onglet Connexion au stockage (attention, les token fournit dans ces scripts d’initialisation expirent rapidement) ;
-
Récupérer les identifiants Vault afin de pouvoir l’utiliser dans votre terminal, disponible dans le sous onglet Vault ;
Information du compte
Dans le sous onglet Information du compte vous retrouverez les informations générales de votre compte Datalab Onyxia GENES et la capacité de modifier le mot de passe pour accéder aux différents services déployer dans votre espace :
Services externes
Dans le sous onglet Services externes vous pourrez récupérer et modifier les informations des comptes et jetons Gitlab, Github et Kaggle qui seront par défaut, lié à tous les services que vous créerez. Par défaut, votre compte datalab est paramétré avec le GitGenes, qui accessible ici.
Nous vous conseillons donc de laisser ces paramètres par défaut, si vous devez utiliser un dépôt git différent (github, bitbucket...) sur un service spécifique, faite la modification lors de la configuration du service dans le Catalogue de services, expliquer plus en détails ici.:
Vous retrouverez également un guide complet sur comment créer et retrouver les informations nécessaires pour la configuration de votre Git sur Github & GitGenes ici.

Connexion au stockage
Dans le sous onglet Connexion au stockage vous trouverez toutes les informations de votre stockage S3 fournit par le GENES et qui sera automatiquement lié à tous les services du datalab que vous créerez. Dans cet onglet vous trouverez également toutes les informations pour connecter vos ressources externes à votre stockage datalab S3.
!!! warning Cependant Attention, tous les tokens de cet onglet expire et se renouvelle automatiquement toutes les 24 heures. Si vous utiliser un token pour connecter des ressources externes a votre stockage S3 datalab, bien se rappeler que la durée de vie des tokens est courte (24h par défaut) et qu'il faudra mettre à jour le token d'accès pour vos ressources externes.
Attention, concernant l’obtention du Session token S3, il n’est pas affiché dans son entièreté, éviter donc de le copier directement en le sélectionnant puis “copier”. Utiliser bien l'icône “Copier dans le presse-papier" à droite de celui-ci :

Vous pourrez également générer un script d’initialisation dans le langage de programmation de votre choix (R, Python, shell, MC client, s3cmd, etc...) qui connectera automatiquement vos ressources à votre stockage datalab S3, disponible en bas à gauche via un menu déroulant :

Vault
Dans le sous onglet Vault, vous aurez la possibilité de copier les variables d’environnement afin de configurer votre Vault CLI local :

!!! warning Attention, concernant l’obtention du token Vault, comme pour le token S3, il n’est pas affiché dans son entièreté, éviter donc de le copier directement en le sélectionnant puis “copier”. Utiliser bien l'icône “Copier dans le presse-papier" à droite de celui-ci :

Modes d’interfaces
Dans le sous onglet Modes d’interfaces vous pourrez modifier le thème du datalab, changer la langue, et activer la fonctionnalités “béta-testeur” qui vous ajoutera les fonctionnalitées du datalab qui ne pas encore complètement operationnel.
Catalogue de services
L’onglet Catalogue de services va vous permettre de lancer, paramétrer et sauvegarder la configuration de vos différents services, qui posséderons plus au moins de sous onglets paramétrables S3, Init, Git etc... qui seront plus détaillé dans la section Configuration avancée du Catalogue de services .
Pour lancer et paramétrer un service, il suffit de cliquer sur “Lancer”.
Chaque service son dans différent sous onglet selon leurs catégories (IDE, Databases etc...), par ailleurs sur quasiment chaque pages web du datalab, peu importe la page. Vous trouverez en haut, une redirection en lien avec la page sur laquelle vous vous trouvez et qui peut vous fournir des informations/guide additionnel.
Par exemple dans le Catalogue de services dans la catégorie Interactive services vous trouverez une redirection vers un dépôt helm qui rassemble la collection des charts helm qu’utilise le datalab pour déployer ses services:

Configuration général du catalogue de services
Dans Catalogue de services après avoir cliquer sur “lancer” du services que vous souhaitez utiliser, vous pourrez : - Attribué un nom personnalisé au service, une fois le service lancé ou enregistré, celui-ci apparaitra dans l’onglet Mes services. - Le choix de la version du service. - Sauvegarder l’entièreté de la configuration du service, que vous pourrez redéployer à volonté dans l’onglet Mes services. - Une extension est cliquable en bas à droite de la page, en parallèle de “Configuration %nom_du_service%”, cela déroulera un menu supplémentaire où vous pourrez configurer beaucoup plus de paramètre qui sont expliqué dans la section suivante disponible ici. - Copier l’URL de lancement automatique, cela vous permettra de configurer un service, puis d’obtenir une URL que vous pourrez partager avec des collaborateurs. En cliquant sur cette URL, cela déploiera le service que vous avez configurer dans leurs espace onyxia. Cette option est aussi accessible dans l’onglet Mes services, sur vos services déjà enregistrés.
Par ailleurs, l’option de la copie URL de lancement automatique ne s’affiche pas avant que vous ayez modifié un paramètre sur le service. L’option “Enregistrer la configuration” s’élargit également lors d’une quelconque modification, sinon c’est une petite icône de sauvegarde situé en haut à droite.

Configuration avancée du Catalogue de services
S3
La configuration par défaut est celle de votre stockage S3 fournit par le groupe GENES, il vous sera donc possible d'accéder aux fichiers stockés directement dans les services de data science (R, Python, Jupyter...) proposés sur le Datalab, sans avoir besoin de copier les fichiers localement au préalable, ce qui améliore fortement la reproductibilité des analyses.
Modifier uniquement ces paramètres si vous possédez par exemple un stockage AWS S3 et que vous souhaitez le monter sur un service Onyxia ou que vous avez besoins d’accéder à un stockage S3 GENES autres que celui qui vous a été attribué par défaut.

Pour apprendre à utiliser cet onglet, voir là page dédiée.
Kubernetes
Cette option est relativement technique et spécifique, vous ne devriez pas en avoir l’intérêt, hors manipulation direct dans l’environnement Kubernetes. Cependant cette option vous permettra, depuis les différents services que vous avez déployés (pods aux seins de votre namespace Onyxia), de pouvoir effectuer des interactions Kubernetes avec le Master Node et exécuter des commandes kubectl dans un terminal de service (kubectl get pods, kubectl edit deployment etc...). Les interactions seront limitées à ce qui est déployé au sein de votre namespace. Vous avez également la possibilité de modifier le rôle Kubernetes attribué aux services, restreignant les actions possibles : view, edit ou admin.
Init
Grâce à Init vous allez pouvoir personnaliser les environnements de vos services via des scripts, qui seront exécuté au lancement de votre services, pour automatiser l’installation d’un plugin sur un de vos services IDE ou autres.
Exemple simple, je souhaite ajouter automatiquement sur mon service datalab Jupyter un fichier .txt avec comme contenu “Hello World” dans le dossier work/hello-onyxia.txt.
Pour cela je créé un script onyxia-init.sh, dont le contenu est le suivant :
#!/monscript.sh
Echo “Hello World” > work/hello-onyxia.txt
!!! warning
Le script est exécuté en tant que superutilisateur (Root) et les fichiers qu'il crée sont ainsi la propriété du superutilisateur.
Ceci génère des erreurs ensuite quand ces fichiers sont appelés, par exemple des fichiers de configuration de RStudio.
Pour rendre à l'utilisateur normal (qui s'appelle onyxia) les droit sur son dossier personnel :
bash chown -R ${USERNAME}:${GROUPNAME} ${HOME}
Ce script peut être hébergé n’importe où, du moment qu’il possède une URL publique (exemple: https://git.drees.fr/drees_code_public/ressources/tutos/-/blob/diffusion/contenu/init.sh) que j’ajoute ensuite dans le Init parameters “PersonalInit” de l’onglet Init:

PersonalInit Ajouter un lien vers un script shell (enchaînement de commandes linux) qui est exécuté juste après le lancement du service. Pratique pour automatiser la mise en place de certaines configurations.
Ce lien du script doit être accessible sur internet, par exemple sur https://code.groupe-genes.fr/ ou autres Git avec un projet public.
Exemple de script d'initialisationqui clone un projet à partir d'une instance Gitlab privée, configure les options globales de RStudio, ouvre automatiquement le projet RStudio cloné, installe et sélectionne la correction orthographique française, personnalise les bribes de codes (snippets).
!!! warning
Le script est exécuté en tant que superutilisateur (Root) et les fichiers qu'il crée sont ainsi la propriété du superutilisateur.
Ceci génère des erreurs ensuite quand ces fichiers sont appelés, par exemple des fichiers de configuration de RStudio.
Pour rendre à l'utilisateur normal (qui s'appelle onyxia) les droit sur son dossier personnel :
bash chown -R ${USERNAME}:${GROUPNAME} ${HOME}
PersonalInitArgs
Des options à passer au script d'initialisation, séparées par des espaces et que l'on peut ensuite appeler avec $1, $2...
Par exemple si on inscrit dans le champ PersonalInitArgs fichier1.txt fichier2.txt, et qu'on utilise ce script d'initialisation :
#!/bin/bash
touch $1
touch $2
Le script créera via la commande touch deux fichiers fichier1.txt et fichier2.txt.
Resources
C’est l’endroit où vous allez pouvoir configurer le minimum à maximum de ressource à vos services, pour rappel, vous êtes limités par compte à 5 services, 20 CPU, 50Go RAM et 1 GPU.

Networking
Cette option permet d’ouvrir un port en particulier sur votre service.

Security
Permet de restreindre l’accès au différent service, filtrer selon IP.
Password : C'est le mot de passe à saisir lorsqu'on ouvre un service, celui donné par "Copier le mot de passage" sur la page des services. Il est fourni par le paramètre général "Mot de passe pour vos services" que l'on trouve dans "Mon Compte" > "Informations du compte", sauf si on en a défini un particulier au niveau du service.
Enable IP protection : Si coché, le service n'est accessible que par une seule IP, à décocher si l'on souhaite travailler de deux endroits différents.
Enable network policy :
Git
Par défaut cette option est activée sur chaque service, ce qui va automatiquement configurer Git et effectuer un clone du dépôt au démarrage du service. Il reprend vos paramètres par défault qui ont été spécifié dans votre compte datalab, voir Mon compte. Attention, vous devez renseigner manuellement l’URL du dépôt Git dans l’option “Repository”.

Un guide complet sur comment créer et trouver les informations d'un dépôt GitHub/GitGenes pour les ajouters sur les services Onyxia est disponible ici.
Repository : Attention, l’option “Repository” est L'URL à renseigner obligatoirement et qui est obtenue sur la plateforme git que vousutilisée (Gitlab, Github...) en cliquant sur "Cloner" > HTTPS:
Par exemple, pour le Github du GENES qui est paramétré par défaut sur votre compte, cette URL sera obtenu sur le lien https://code.groupe-genes.fr/aguyot-ensae/test-gitop puis en cliquant sur l’icône “Copier l’URL”. Vous obtiendrez l’URL https://code.groupe-genes.fr/aguyot-ensae/test-gitop.git à renseigner dans l’option “Repository”, ce qui clonera ce dépôt automatiquement sur votre service :

Exemple sur un service Jupyter où l’URL du dépôt a été renseigné et donc cloné au démarrage :

Name : Le nom qui apparaîtra dans les commits (pas le nom d'utilisateur du compte Gitlab ou Github).
Email : L'adresse email qui apparaîtra dans les commits (pas forcément le mail associé au compte Gitlab ou Github).
Token : Jeton d'accès défini sur la plateforme utilisée (Gitlab, Github...).
Pour apprendre à utiliser plus en détails cette partie de Git, voir là page dédiée.
Il n'est pas possible de cloner automatiquement un projet privé d'une instance privée (c'est-à-dire autre que gitlab.com et github.com). Pour le faire, il faudra recourir à un script shell comme indiqué plus de détails ici.
Service
Ici vous pouvez sélectionner l'image docker qui sera utilisé pour la configuration du service et également en spécifier une custom. Cependant les fonctionnalitées de cet onglet sont actuellement limitées et l'utilisation d'une image custom ne marchera pas, vous avez uniquement le choix de sélectionner des images utilisés par le datalab dans le menu déroulant Version

PullPolicy Politique de déploiement de l'image du service, vous avez le choix entre 3 options: - IfNotPresent: le service utilisera l'image sélectionnée dans cet onglet uniquement si l'image par défaut utilisé par le datalab n'est pas récupérable - Always: le service utilisera l'image sélectionnée dans cet onglet - Never: le service n'utilisera pas l'image sélectionnée dans cet onglet
Version Permet de sélectionner la version d'image qu'utilisera le service, ces images sont les officiels utilisées par le datalab.
Custom image Permet de spécifié l'utilisation d'une image custom, cependant cette fonctionnalitée est actuellement désactivée.
Discovery
Les différentes options du discovery sont activées, elles permettent de détecter si vous avez un service Hive metastore, mlflow ou metaflow de lancer et d’automatiquement les rattacher à votre service.

Persistence
Vous permet de modifier la taille du disque alloué à votre service.
Vault
Pour apprendre à utiliser cet onglet, voir la page dédiée et Vault.
Mes services
Dans l'onglet Mes services vous retrouverez tous vos services en cours, lesquels vous pourrez ré-accéder ou les supprimers. Vous retrouvez aussi les configurations des services que vous avez enregistrer que vous pourrez relancer, modifier ou partager via URL leurs configuration. Par exemple dans le cas d'un enseignant, cela lui permettra de configurer un service comme il le souhaite, pour ensuite partager l'URL à ces étudiants, ce qui va leurs permettre de déployer automatiquement dans leurs services un environnement de travail entièrement pré-configurer, stable et reproductible.
Dans l'onglet "Mes services" de la plateforme Onyxia, vous avez accès à la liste complète de vos services actifs, que vous pouvez ré-ouvrir ou supprimer à votre convenance. De plus, vous pouvez modifier et relancer les configurations enregistrées de services que vous avez sauvegarder et pouvez les relancer, modifier, ou partager via une URL spécifique.

Le partage de l'URL va permettre, par exemple, pour un enseignant, de personnaliser un service selon ses besoins pour un cours, puis de partager l'URL de la configuration avec les étudiants. Ces derniers peuvent ainsi déployer automatiquement un environnement de travail préconfiguré, stable et reproductible dans leurs environnement datalab respectifs.
!!! warning Penser à supprimer vos services une fois que vous ne les utilisez plus. Un service lancé sur notre infrastructure Onyxia alloue des ressources, et en libérant ces ressources lorsque le service n'est plus nécessaire, vous contribuez à une utilisation plus efficace et responsable de l'infrastructure du datalab.
Grafana
Grafana est un outil de surveillance et de visualisation des données qui offre la possibilité de suivre et d'analyser les performances des différents services que vous avez lancés dans votre espace personnel ou groupe projet sur le datalab.

Mes secrets
Les variables d’environnement, il arrive que certaines informations doivent être mise à disposition d’un grand nombre d’applications, ou ne doivent pas figurer en clair dans votre code (jetons d’accès, mots de passe, etc.). L’utilisation de variables d’environnement permet de pouvoir accéder à ces informations depuis n’importe quel service.
Pour apprendre à utiliser cet onglet, voir la page dédiée.
Mes fichiers
La page Mes fichiers du Datalab prend la forme d'un explorateur de fichiers présentant les différents buckets (dépôts) auxquels l’utilisateur a accès. Chaque utilisateur dispose par défaut d'un bucket personnel pour stocker ses fichiers, l'interface de stockage S3 est également accessible ici.
Il est possible de lire directement vos fichiers depuis cette interface en double cliquant simplement dessus (.mp4, .parquet, .csv etc...), si le format n'est pas lisible depuis l'interface du datalab, cela vous téléchargement automatiquement le fichier.
Pour apprendre à utiliser cet onglet, voir la page dédiée.
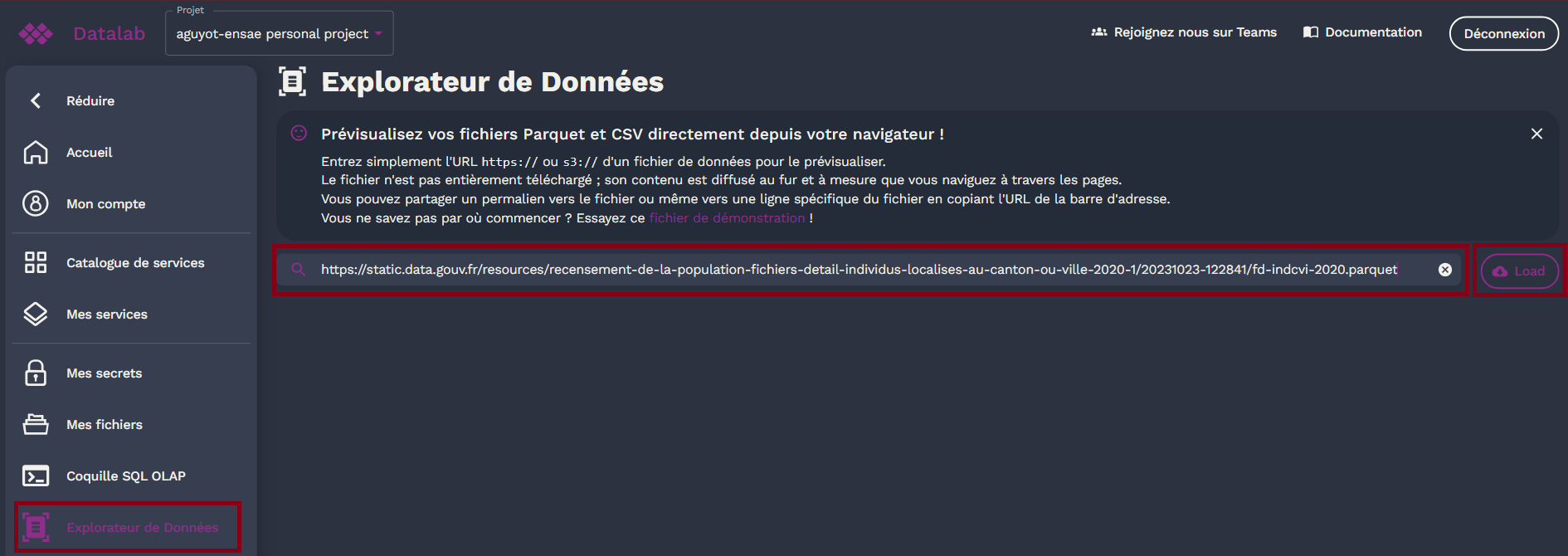
Explorateur de Données
L'explorateur de données vous permet de prévisualisez vos fichiers parquet et CSV directement depuis le navigateur du datalab, afin d'éviter de devoir passer par un service jupyter ou autres.
Vous pourrez ainsi lire des données qui sont stockées sur votre stockage S3 également accessible dans votre onglet Mes fichiers ou en utilisant une URL publique d'un fichier donnée pour le prévisualiser, ci dessous deux exemples pour importer des données:
Depuis mon stockage S3:
Rien de plus simple, si votre fichier est stocké dans Mes fichiers, il vous suffira de double cliquer directement dessus et celui-ci s'ouvrira automatiquement:

Depuis une URL
Il faut que vous stocker votre fichier et que celui-ci soit partageable via une adresse URL https://, de l'ajouter dans "DATA SOURCE" de l'onglet Explorateur de données et de cliquer sur "LOAD". Par exemple pour le fichier parquet disponible depuis l'URL: https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet